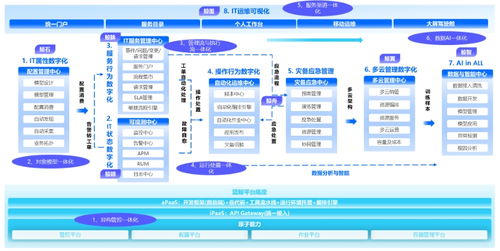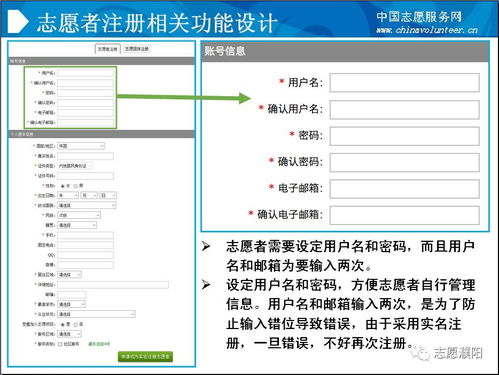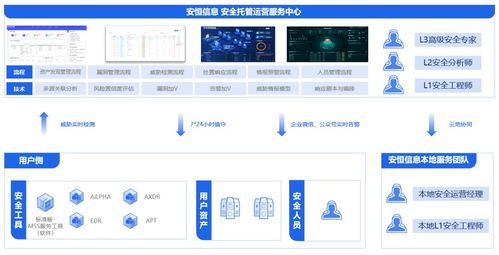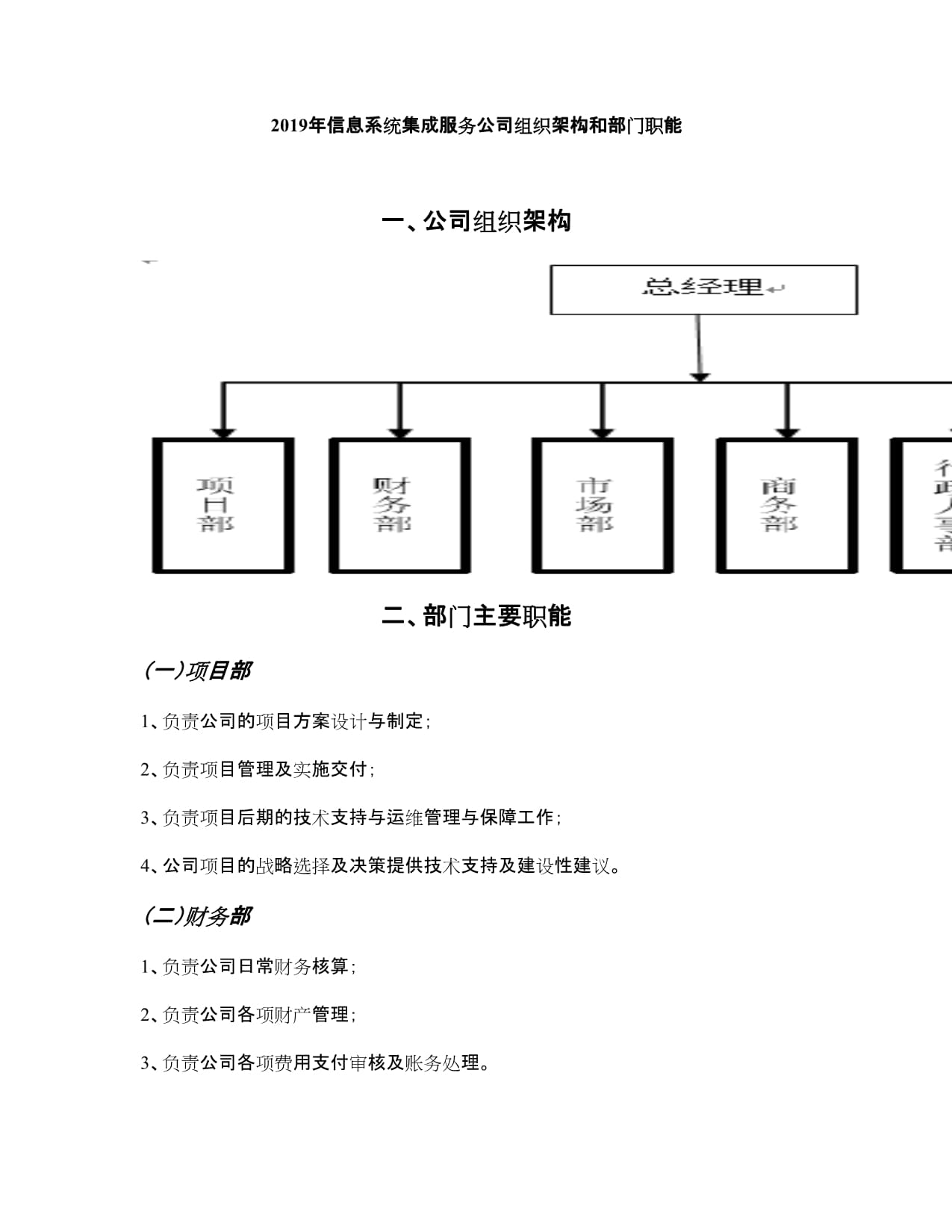
在基于微服務架構的信息系統集成服務中,服務間通過消息隊列進行異步通信是一種常見且高效的解耦方式。這種異步、分布式的調用模式也給調試帶來了獨特的挑戰。本文將結合CSDN上相關實踐經驗,系統性地探討如何有效調試微服務間通過消息隊列進行的監聽調用。
1. 理解調試的難點與核心
在同步調用(如REST API)中,調用鏈清晰,錯誤往往能即時返回。但在消息隊列場景下,調試的核心難點在于:
- 調用鏈斷裂:生產者發出消息后即“忘記”,與消費者的處理過程在時間和空間上分離。
- 狀態不可見:消息在隊列中的狀態、消費者的處理進度和結果不易直接觀察。
- 問題復現困難:異步環境下,消息的時序、網絡抖動、服務重啟等因素使得問題可能難以穩定復現。
因此,調試的重點應從傳統的“單步跟蹤”轉變為對消息流和服務狀態的全局監控與追蹤。
2. 構建可觀察性基礎設施
這是有效調試的基石,需要從三個維度著手:
a. 全面的日志記錄
- 結構化日志:在每個服務的消息處理入口和出口(以及關鍵業務步驟)記錄結構化日志(如JSON格式),必須包含唯一的追蹤ID(Trace ID)、消息ID、時間戳、服務名、處理狀態(成功/失敗)及錯誤詳情。
- 關聯日志:確保生產者生成消息時創建的Trace ID能通過消息頭(Headers)傳遞給消費者,從而在日志聚合平臺(如ELK、Loki)中能通過該ID串聯起完整的處理鏈路。
b. 分布式鏈路追蹤
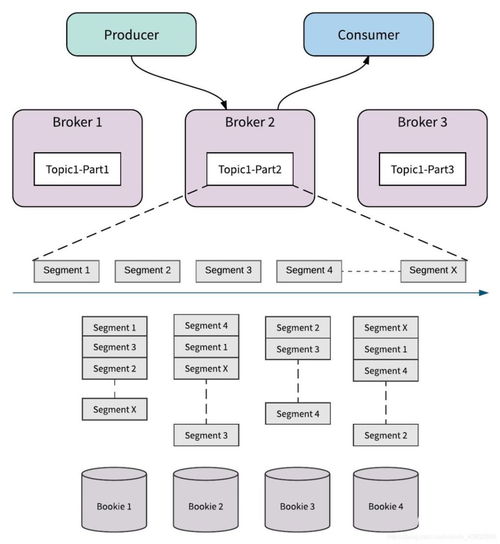
- 集成如Jaeger、SkyWalking、Zipkin等工具。它們能自動或通過少量代碼注入,追蹤消息從生產、隊列中轉、到消費的完整路徑,并以可視化形式展示耗時、服務依賴和錯誤點。
c. 指標監控與告警
- 監控關鍵指標:消息生產/消費速率、隊列積壓長度、處理耗時、錯誤率。
- 設置告警:當錯誤率飆升、隊列積壓超過閾值或平均處理耗時異常時,立即通知開發人員。
3. 具體的調試策略與方法
a. 消息的“重放”與“注入”
- 重放:當發現某條消息處理失敗時,可以從消息隊列的管理界面(如RabbitMQ的Management UI、Kafka的Kowl)或通過備份的日志中,復制出原始消息體(Payload)和消息頭。
- 注入:在測試或預發布環境中,通過編寫臨時腳本或使用工具(如kafkacat、rabbitmqadmin),將該消息重新發布到對應的隊列中,觀察消費者行為,進行復現和調試。這是最直接的復現手段。
b. 搭建與生產環境一致的調試環境
- 使用Docker Compose或Kubernetes在本地或開發機部署一套包含所有相關微服務、相同版本的消息隊列中間件的完整環境。這樣可以安全地進行破壞性測試和單步調試。
c. 使用消息隊列的延遲與死信隊列
- 配置消費者的失敗重試機制,并將經過最大重試次數后仍然失敗的消息投遞到死信隊列。調試時,可以專門監聽死信隊列,分析其中的“毒藥消息”,是調試消費邏輯錯誤的寶貴來源。
d. 模擬與集成測試
- 單元測試:對消費者的消息處理函數進行充分的單元測試,模擬各種正常的和畸形的輸入。
- 集成測試:編寫自動化測試用例,啟動真實的消息隊列容器(如Testcontainers),運行從生產消息到消費驗證的完整流程。
e. 交互式調試
- 在本地開發時,可以讓消費者服務連接到開發或測試環境的消息隊列,直接消費實時消息進行調試。(注意:需嚴格避免污染生產數據)
- 利用IDE的遠程調試功能,附加到運行在測試環境的消費者服務實例上,在消費消息時設置斷點,檢查內部狀態。
4. 利用工具提升效率
- 消息隊列管理工具:熟練使用RabbitMQ Management Plugin、Kafka Manager、Kafdrop等,實時查看隊列狀態、瀏覽消息內容。
- API調試工具增強:對于HTTP API觸發的消息生產,使用Postman或Apifox等工具模擬請求,并關聯查看后端產生的消息。
- 專門的微服務調試平臺:如Arthas(Java)可用于在線診斷運行中的服務,檢查消息處理線程的狀態和變量。
5. 建立調試文化
調試消息隊列通信不僅是技術活動,也需流程保障:
- 設計時考慮可調試性:在架構設計階段,就約定好日志規范、Trace ID傳遞方式和錯誤處理機制。
- 文檔化常見問題:在團隊Wiki或CSDN等技術社區記錄典型的消息隊列相關故障案例、排查步驟和解決方案,形成知識庫。
- 故障演練:定期模擬消息丟失、重復消費、隊列積壓等故障,訓練團隊的應急響應和調試能力。
通過構建強大的可觀測性體系,并結合主動的測試、復現和交互式調試方法,可以顯著降低微服務間消息通信的調試復雜度,保障信息系統集成服務的穩定與高效運行。